Company Data API für AI Agents:
Was „agent-ready“ wirklich heißt
AI Agents scheitern in der Praxis oft nicht am Modell, sondern an den Daten: uneinheitliche Identitäten, veraltete Fakten, fehlende Beziehungen und zu wenig Nachvollziehbarkeit.
Wenn ein AI Agent ein Unternehmen eindeutig identifizieren, verlässliche Unternehmensfakten abrufen und Outputs liefern soll, die Ihr Team prüfen und reproduzieren kann, reicht „ein bisschen Enrichment“ oft nicht aus.
Dann brauchen Sie eine agent-ready Company Data API (oft auch „Business Data API“ genannt), die auf zuverlässige, wiederholbare Automatisierung ausgelegt ist.
In diesem Guide erfahren Sie:
-
was „agent-ready“ bei Unternehmensdaten bedeutet,
-
wie Sie Anbieter vergleichen,
-
und welche Minimum-Logs Sie speichern sollten, damit AI Agents produktionsreif bleiben.
Kurzdefinition: Company Data API vs. Business Data API
Eine Company Data API liefert typischerweise strukturierte Fakten zu Rechtsträgern: Identifikatoren, Name, Adresse, Statussignale und Beziehungen (z. B. Hierarchien; Ownership/UBO je nach Kontext).
Eine Business Data API wird häufig breiter verwendet – als Begriff für Unternehmensdaten, die in kommerziellen Workflows genutzt werden (Enrichment, Segmentierung, Hierarchie-Mapping). In der Praxis ist die Grenze fließend.
Für AI Agents zählt vor allem: strukturierte Fakten mit stabilen IDs, konsistentem Schema und – wenn verfügbar – Quelle + Zeitstempel.
TL;DR
-
AI Agents brechen bei Unternehmensdaten meist an Identität, Freshness und fehlender Nachvollziehbarkeit.
-
„Agent-ready“ heißt: stabile IDs, Matching, normalisierte Felder, Relationship-Kontext und Evidenz-Metadaten.
-
Nutzen Sie die Checkliste unten, bevor Sie integrieren – das spart Monate.
Warum AI Agents an Unternehmensdaten scheitern (5 typische Failure Modes)
1) Identitätsproblem (Entity Resolution)
„ACME GmbH“ ≠ „Acme Gmbh“ ≠ „ACME Holding“. Das ist kein Sprachproblem, sondern ein ID-Problem. Ohne stabile Identifikatoren und Disambiguation-Signale verknüpfen Agents Fakten mit der falschen Entität.
Insight: Viele „Halluzinationen“ sind in Wahrheit falsch gematchte Unternehmen.
2) Veraltete Fakten ohne „As-of“-Klarheit
Ein Fakt ohne Zeitbezug ist riskant. Teams müssen wissen: Stand wann?
Sobald ein AI Agent Entscheidungen vorbereitet (Routing, Freigaben, Risiko-Kontext), wird „Freshness“ zur QA-Anforderung.
3) Fehlende oder unbrauchbare Beziehungen
Viele Workflows hängen an Hierarchien: Muttergesellschaft, Tochtergesellschaften, Gruppenstrukturen.
Wenn das nur als Text kommt, können Agents kaum zuverlässig über Beziehungen „reasonen“.
4) Kein Provenance-/Evidence-Layer
Spätestens im Review fragt jemand: „Woher kommt diese Information?“
Ohne Quellen- und Nachvollziehbarkeit wird aus Automatisierung schnell wieder manuelle Recherche.
5) Inkonsistentes Schema
Wenn Felder mal da sind, mal fehlen, oder Formate schwanken, verbringt der Agent mehr Zeit mit „Parsing“ als mit Arbeit.
Insight: Schema-Konsistenz ist der Unterschied zwischen Demo-Agent und Produktionssystem.
Was „agent-ready“ konkret heißt: Mindestanforderungen an eine Unternehmensdaten API
Eine agent-ready Company Data API liefert nicht nur Daten, sondern schafft Verlässlichkeit für Automatisierung:
-
stabile Entity IDs, die Sie speichern und wiederverwenden können
-
Matching + Disambiguation, damit der Agent die richtige Entität findet
-
normalisierte Felder, damit Outputs konsistent verarbeitet werden können
-
Freshness-Metadaten (as-of / last updated + klare Refresh-Policy)
-
Relationships, z. B. Hierarchien/Links und Ownership (wo anwendbar)
-
Evidence-/Traceability-Metadaten (Quelle/Provenance, wo verfügbar)
-
Coverage-Klarheit, was pro Land/Quelle enthalten ist – und was nicht
Agent-Ready Checkliste: Company Data API / Business Data API
Nutzen Sie diese Checkliste als Mindeststandard:
-
Stabile Entity IDs (persistente IDs, die Sie speichern und wiederverwenden können)
-
Entity Matching (Suche + Disambiguation über exakte Namenssuche hinaus)
-
Normalisiertes Schema (konsistente Felder und Datentypen)
-
Freshness-Metadaten (as-of/last updated + klare Refresh-Policy)
-
Evidence-/Traceability-Metadaten (Quelle/Provenance, wo verfügbar)
-
Relationships (Hierarchie/Links; Ownership wo anwendbar)
-
Coverage-Klarheit (was ist pro Land/Quelle enthalten – und was nicht)
-
Integration-Readiness (Docs, Pagination, Rate Limits, Error Semantics)
-
QA-fähiges Logging (Outputs so, dass Entscheidungen nachvollziehbar bleiben)
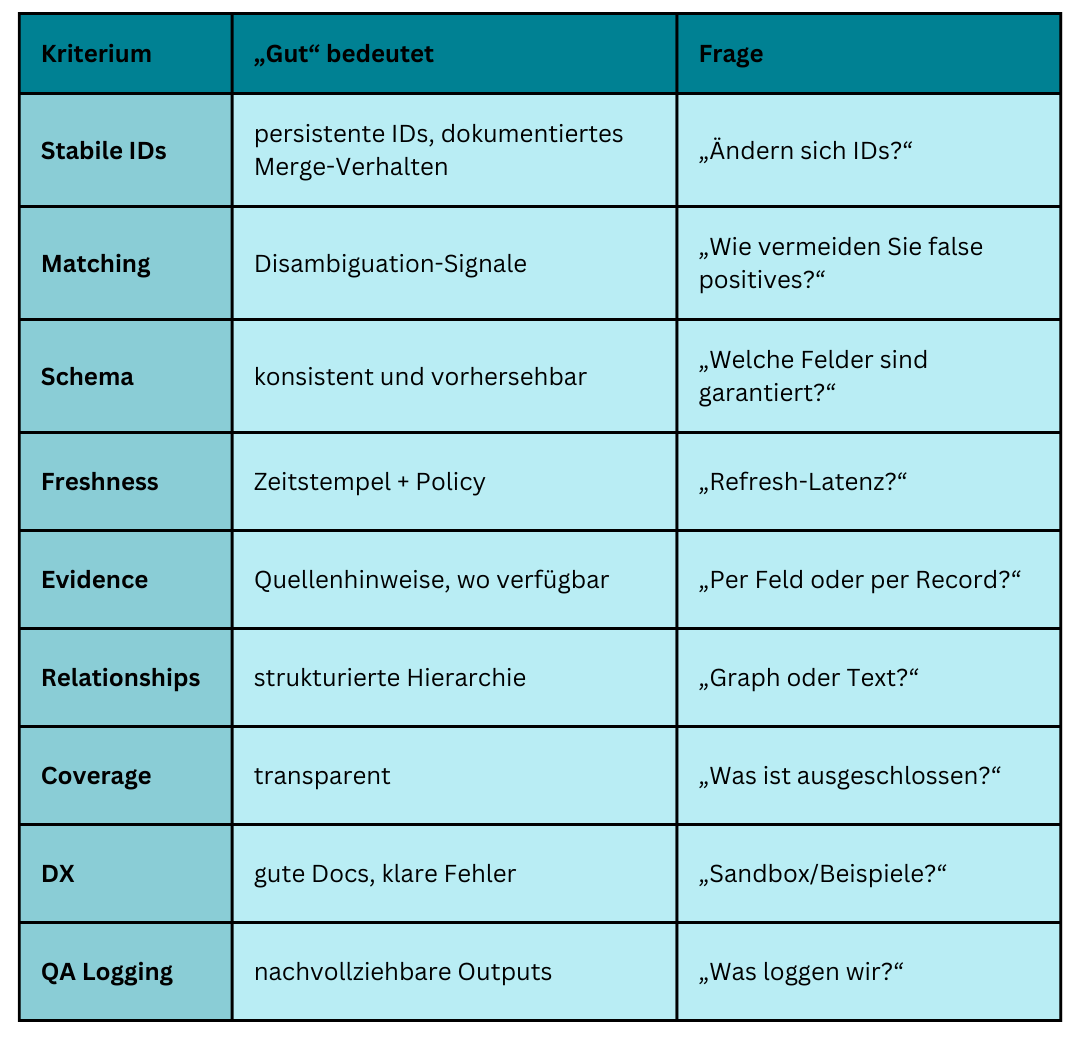
Die Anbieterfragen, die Ihnen Monate sparen
Viele Teams fragen „Welche Daten haben Sie?“. Besser sind diese Fragen:
-
Ändern sich IDs? Was passiert bei Merges/Dedupes?
-
Wie reduzieren Sie False Matches? Welche Signale liefern Sie zur Disambiguation?
-
Welche Felder sind garantiert? Was ist optional?
-
Was ist Ihre Refresh-Policy? Welche Latenz ist realistisch?
-
Gibt es Zeitstempel pro Datensatz (oder pro Feld)?
-
Gibt es Quellen-/Provenance-Infos? (per Record/Feld, wo verfügbar)
-
Wie sind Hierarchien modelliert? Graph/Links vs. Text?
-
Was sind die Top-Failure-Cases? (z. B. Namensgleichheit, Holding-Strukturen)
-
Wie sieht ein „Safe Fallback“ aus? (Human Review Flag statt Halluzination)
-
Was sollen wir für QA loggen?
Evaluation-Tabelle
Drei produktive Agent-Workflows, die von agent-ready Company Data profitieren
1) RevOps / Account Research Agent
Ziel: Enrichment, Dedupe, Hierarchie-Mapping für Routing/Segmentierung.
Kritisch: Matching + stabile IDs + Hierarchielinks.
Ablauf:
-
Suche nach Company Name + Land
-
Disambiguation (Adresse/IDs/Metadaten)
-
Persistente ID speichern
-
Profil + Hierarchie abrufen
-
Strukturierte Outputs ins CRM + Agent Log schreiben
2) Vendor / Supplier Onboarding Agent
Ziel: Rechtsträger verifizieren, Rückfragen reduzieren.
Kritisch: normalisierte Fakten + Freshness + nachvollziehbare Outputs.
Ablauf:
-
Entität identifizieren
-
Kernfakten verifizieren (Name/Adresse/Status)
-
Zeitstempel & (wo verfügbar) Quelleninfos am Datensatz speichern
-
Unklare Fälle automatisch in Human Review routen
3) Counterparty / Risk Context Agent (KYB-lite)
Ziel: „Company Facts Package“ für Reviewer erstellen.
Kritisch: stabile IDs + Relationships + Evidence-Metadaten.
Was Sie mindestens loggen sollten (Minimum Viable Traceability)
Auch außerhalb strikter Compliance verbessert das QA massiv:
-
Entity ID (stabil)
-
Input Query (wonach gesucht wurde)
-
Zeitstempel (wann geprüft)
-
Strukturierte Fakten (Output)
-
Evidence-Metadaten (Quelle, wo verfügbar)
-
Entscheidung + Eskalationsgrund (z. B. „ambiguous match“)
Praxisregel: Wenn ein Mensch das Ergebnis nicht reproduzieren kann, wird der Agent in Produktion früher oder später brechen.
Der nicht offensichtliche Insight: „Agent Accuracy“ ist oft Daten-Engineering
Wenn AI Agents zuverlässig sein sollen:
-
behandeln Sie Entity Resolution als first-class feature
-
behandeln Sie Zeitstempel als Contract
-
behandeln Sie Beziehungen als Daten, nicht als Narrativ
-
designen Sie Outputs für Traceability, nicht nur für Lesbarkeit
Genau deshalb standardisieren viele Teams auf eine Company Data API, die für Automatisierung gebaut ist – statt auf Datenquellen, die primär für menschliches Browsing optimiert sind.
So integrieren Teams Company Data APIs in Agent-Workflows
Wenn Teams eine Company Data API / Business Data API evaluieren, geht es fast immer um dieselben Basics: stabile IDs, konsistente (normalisierte) Outputs, Relationship-/Hierarchie-Kontext und – wo möglich – Traceability über Quelle und Zeitstempel.
Genau dafür ist die Company.info API ausgelegt: als Datenlayer, der strukturierte Unternehmensfakten so bereitstellt, dass sie in Agent-Workflows zuverlässig verarbeitet werden können – und Ergebnisse in QA nachvollziehbar bleiben.
Wenn Sie aktuell AI Agents bauen, die saubere Unternehmensidentität, Hierarchy Mapping oder belastbare Company Facts benötigen, vergleichen Sie gerne mit der Checkliste oben. Auf Wunsch senden wir Ihnen eine kurze „Agent-Ready Evaluation Sheet“-Version, abgestimmt auf Ihren konkreten Use Case.
Kurz zusammengefasst: Eine agent-ready Company Data API liefert stabile IDs, Matching, ein normalisiertes Schema, Freshness-Zeitstempel, Relationship-Daten und – wo verfügbar – Evidence-/Traceability-Metadaten.
Die Company.info API ist darauf ausgelegt, Agent-Workflows mit strukturierten Unternehmensdaten zu versorgen – inklusive stabiler Entity IDs, konsistenter Felder und (wo verfügbar) Zeitstempeln sowie Quellenhinweisen/Verlinkungen auf offizielle Dokumente. Abdeckung und Evidenzdetails variieren je nach Land und Quelle.
Company.info ist dabei der Daten- und Evidenzlayer – die Orchestrierung und Entscheidungslogik liegt in Ihrem Agent bzw. Workflow.
Möchten Sie prüfen, ob Ihre AI-Agent-Workflows mit einer Company Data API stabiler werden?